文件操作
文件类型
按数据的组织形式可以把文件分为文本文件和二进制文件两大类。
文本文件
文本文件存储的是常规字符串,由若干文本行组成,通常每行以换行符”\n”结尾。
常规字符串是指记事本之类的文本编辑器能正常显示、编辑并且人类能够直接阅读和理解的字符串,如英文字母、汉字、数字字符串。在win平台中扩展名为txt、log、ini都是文本文件,可以使用字处理软件如记事本等进行编辑。
实际上文本文件在磁盘上也是以二进制形式存储的。只是在读取和查看时使用正确的编码方式进行解码,还原为字符串信息,所以可以直接阅读和理解。
二进制文件
常见的如图形图像文件、音视频文件、可执行文件、资源文件、各种数据库文件、各类office文档等都属于二进制文件。
二进制文件把信息以字节串进行存储,无法用记事本或其他普通字处理软件直接进行编辑,通常也无法直接阅读和理解,需要使用正确的软件进行解码或反序列化之后才能正确地读取、显示、修改或执行。无法使用记事本查看,显示乱码。
文件操作的主要方法
open() 方法
Python open() 方法用于打开一个文件,并返回文件对象。
在对文件进行处理过程都需要使用到这个函数,如果该文件无法被打开,会抛出 OSError。
注意:使用 open() 方法一定要保证关闭文件对象,即调用 close() 方法。
open() 函数常用形式是接收两个参数:文件名(file)和模式(mode)。
open(file, mode='r')
完整的语法格式为:
open(file, mode='r', buffering=-1, encoding=None, errors=None, newline=None, closefd=True, opener=None)
参数说明:
- file: 必需,文件路径(相对或者绝对路径)。
- mode: 可选,文件打开模式
- buffering: 设置缓冲
- encoding: 一般使用utf8
- errors: 报错级别
- newline: 区分换行符
- closefd: 传入的file参数类型
- opener: 设置自定义开启器,开启器的返回值必须是一个打开的文件描述符。
mode 参数有:
| 模式 | 描述 |
|---|---|
| t | 文本模式 (默认)。 |
| x | 写模式,新建一个文件,如果该文件已存在则会报错。 |
| b | 二进制模式。 |
| + | 打开一个文件进行更新(可读可写)。 |
| r | 以只读方式打开文件。文件的指针将会放在文件的开头。这是默认模式。 |
| rb | 以二进制格式打开一个文件用于只读。文件指针将会放在文件的开头。这是默认模式。一般用于非文本文件如图片等。 |
| r+ | 打开一个文件用于读写。文件指针将会放在文件的开头。 |
| rb+ | 以二进制格式打开一个文件用于读写。文件指针将会放在文件的开头。一般用于非文本文件如图片等。 |
| w | 打开一个文件只用于写入。如果该文件已存在则打开文件,并从开头开始编辑,即原有内容会被删除。如果该文件不存在,创建新文件。 |
| wb | 以二进制格式打开一个文件只用于写入。如果该文件已存在则打开文件,并从开头开始编辑,即原有内容会被删除。如果该文件不存在,创建新文件。一般用于非文本文件如图片等。 |
| w+ | 打开一个文件用于读写。如果该文件已存在则打开文件,并从开头开始编辑,即原有内容会被删除。如果该文件不存在,创建新文件。 |
| wb+ | 以二进制格式打开一个文件用于读写。如果该文件已存在则打开文件,并从开头开始编辑,即原有内容会被删除。如果该文件不存在,创建新文件。一般用于非文本文件如图片等。 |
| a | 打开一个文件用于追加。如果该文件已存在,文件指针将会放在文件的结尾。也就是说,新的内容将会被写入到已有内容之后。如果该文件不存在,创建新文件进行写入。 |
| ab | 以二进制格式打开一个文件用于追加。如果该文件已存在,文件指针将会放在文件的结尾。也就是说,新的内容将会被写入到已有内容之后。如果该文件不存在,创建新文件进行写入。 |
| a+ | 打开一个文件用于读写。如果该文件已存在,文件指针将会放在文件的结尾。文件打开时会是追加模式。如果该文件不存在,创建新文件用于读写。 |
| ab+ | 以二进制格式打开一个文件用于追加。如果该文件已存在,文件指针将会放在文件的结尾。如果该文件不存在,创建新文件用于读写。 |
默认为文本模式,如果要以二进制模式打开,加上 b 。
file 对象常用的函数
file.close()
关闭文件,关闭后文件不能再进行读写操作。
file.read([size])
从文件读取指定的字节数,如果未给定或为负则读取所有。
file.readline([size])
读取整行,包括 "\n" 字符。
file.readlines([sizeint])
读取所有行并返回列表,若给定sizeint>0,返回总和大约为sizeint字节的行, 实际读取值可能比 sizeint 较大, 因为需要填充缓冲区。
file.seek(offset[, whence])
seek() 方法用于移动文件读取指针到指定位置
fileObject.seek(offset[, whence])offset -- 开始的偏移量,也就是代表需要移动偏移的字节数
whence:可选,默认值为 0。给offset参数一个定义,表示要从哪个位置开始偏移;0代表从文件开头开始算起,1代表从当前位置开始算起,2代表从文件末尾算起。
file.tell()
返回文件当前位置。
file.write(str)
将字符串写入文件,返回的是写入的字符长度。
file.writelines(sequence)
向文件写入一个序列字符串列表,如果需要换行则要自己加入每行的换行符。
文件的基础操作
一般文件的读写:
写文件
1.第一步:打开文件
f=open('test.txt','w') #test.txt文件和代码文件保存在一个路径下
2.第二步:写文件
f.write('要写的内容')
f.writelines(序列-比如列表)
3.第三步:关闭文件
f.close()
读文件
1.打开文件
f=open(r'd:\test.txt','r') #指定文件路径,字符串前面加“r”是为了防止字符转义,
2.读文件
c=f.read() #读取全部内容到字符串变量c中
c=f.readline() #读取一行,再次调用则读写下一行
c=f.readlines() #读取全部行到列表c中
3.关闭文件
f.close()
with语句打开文件
前面使用open打开文件,不论是读还是写,都必须调用close()方法关闭文件,否则资源就会一直被该程序占用而无法被释放。
关键字with可以自动管理资源,不论因为什么原因,哪怕是代码引发了异常跳出with块,总能保证文件被正确关闭,可以在代码块执行完毕后自动还原进入该代码块时的上下文。用于文件内容读写时,with语句的用法如下:
with open(file,mode,encoding) as fp:
#读写内容
例:
with open("test.txt", "wt") as out_file:
out_file.write("该文本会写入到文件中\n看到我了吧!")
with open("test.txt", "rt") as in_file:
text = in_file.read()
print(text)
csv模块使用:
CSV文件:Comma-Separated Values,中文叫逗号分隔值或者字符分割值,其文件以纯文本的形式存储表格数据。可以把它理解为一个表格,只不过这个表格是以纯文本的形式显示的,单元格与单元格之间,默认使用逗号进行分隔;每行数据之间,使用换行进行分隔。
name,age,score
zhangsan,18,98
lisi,20,99
wangwu,17,90
jerry,19,95
python自带csv模块,直接导入使用即可,导入方式如下:
import csv
写文件:writer()
import csv
with open('xxxx.csv','w',newline='') as f:
writer = csv.writer(f) #创建初始化写入对象
writer.writerow(['color','red']) # 一行一行写入
writer.writerows([('color','red'), ('size','big'),('male','female')]) #多行写入
注意:在Windows里保存的CSV文件是每空一行存储一条数据,使用newline=”可保证存储的数据没有空行。
读文件:
import csv
with open("xxxx.csv",'r') as f:
rows = list(csv.reader(f))
print(rows)
读取csv字典
csv.DictWriter方法
在Python中,还有一个写入CSV文件的方法csv.DictWriter,可以使用该方法向CSV文件中写入数据,并保存为CSV格式。它也可以指定分隔符和引号类型。
具体的代码如下:
import csv
with open('example.csv', 'w', newline='') as csvfile:
fieldnames = ['name', 'age', 'gender']
writer = csv.DictWriter(csvfile, fieldnames=fieldnames)
writer.writeheader()
writer.writerow({'name': 'Jack', 'age': '25', 'gender': 'Male'})
writer.writerow({'name': 'Lucy', 'age': '23', 'gender': 'Female'})
这段代码将会向example.csv文件中写入数据,并将内容保存为CSV格式,执行后文件内容如下:
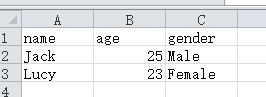
csv.DictReader方法
csv.DictReader方法是csv模块中对于CSV文件进行读操作的方法,它可以按照行读取CSV文件中的数据,返回的结果是一个字典。
DictReader方法的使用方式如下代码所示:
import csv
with open('example.csv', newline='') as csvfile:
reader = csv.DictReader(csvfile)
for row in reader:
print(row)
该代码会读取同级目录下的example.csv文件,并打印每行的字典信息,其中newline参数是为了避免Windows系统下文件读写的问题。为读取CSV文件时打开文件的参数中需要添加newline参数。
输出内容如下:
OrderedDict([('name', 'Jack'), ('age', '25'), ('gender', 'Male')])
OrderedDict([('name', 'Lucy'), ('age', '23'), ('gender', 'Female')])
一维数据的读写
将列表对象输出为CSV格式文件,示例如下。
c=['北京','上海','广州','深圳']
f=open('city.csv','w')
f.write(','.join(c)+'\n')
f.close()
注意:f.close()如果不写,则写的内容不能保存的文件中。
从csv格式文件中读出数据,表示为列表对象,示例如下。
f=open('city.csv','r')
c=f.read().strip().split(',')
f.close()
print(c)
上述代码用with语句改写如下。
with open('city.csv','r') as f:
c=f.read().strip().split(',')
print(c)
二维数据的读写
将列表对象输出为csv格式,示例如下。
c=[
['张三','95','98','78','65'],
['李四','85', '89', '68', '93'],
['王五','99', '89', '86', '90'],
]
f=open('cj.csv','w')
for i in c:
f.write(','.join(i) + '\n')
f.close()
从CSV格式文件读出数据,表示为列表对象,示例如下。
f=open('cj.csv','r')
c=[]
for i in f:
c.append(i.strip('\n').split(','))
f.close()
print(c)
[['张三','95', '98', '78', '65'],[
'李四’,’85', '89', '68', '93'],['
王五'99', '89', '86', '90']]
文件操作案例
案例一 读取IP文件
请读取文件IP.txt的数据,数据内容如下图显示:

文件中每一行存储一个IP地址,下列代码实现了读取数据,每次读取一行数据,都删除了行末的换行符,最后逆序输出文件中的每行IP地址,请你补全代码。
输出参考如下:
49.97.132.119 32.33.23.232 112.114.44.44
参考程序:
with open('IP.txt', 'r') as f:
list = f.readlines()
for i in len(list) range(0, ):
list[i] = list[i].strip('\n')
for i in range(len(list)-1,-1,-1):
print(list[i])
f.close()
案例二 运动时间数据
小文的运动时间数据存储在文件“sport.csv”中,数据内容如下图显示:
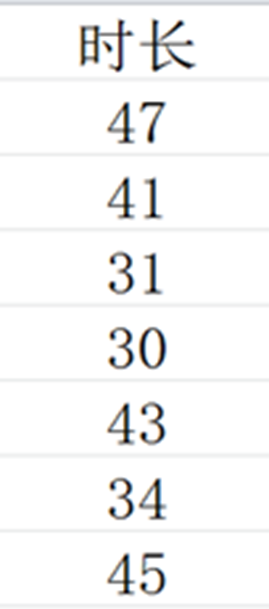
下列代码实现了读取数据,求和并统计个数,输出平均时长,并保留2位小数,请你补全代码。
参考程序:
import csv
with open("sport.csv") as f:
rows = list(csv.reader(f))
s=0
c=0
for row in rows[1:]:
s+=int(row[0])
c=c+1
print(round(s/c,2))
案例三 身高数据
请读取文件subways.csv的数据,数据内容如下图显示:
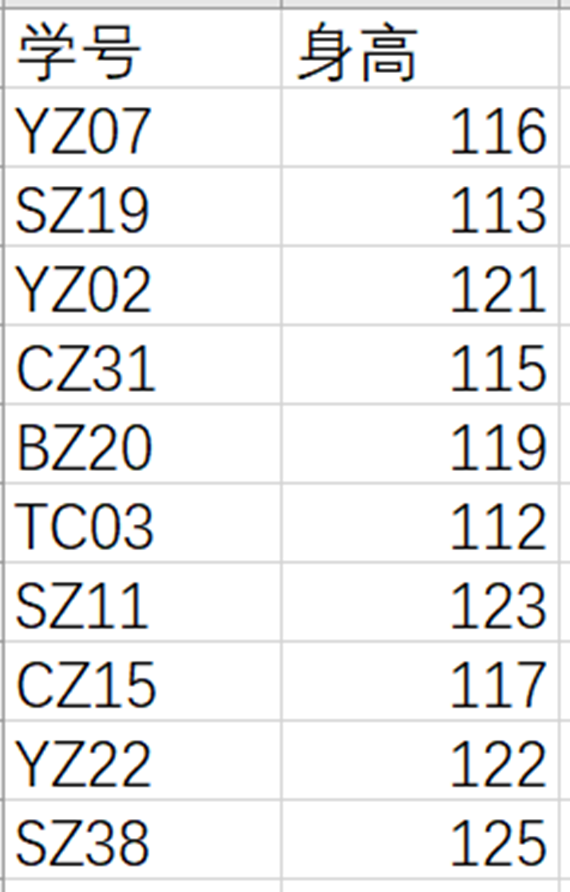
下列代码实现了读取“学号”和“身高”信息,输出“身高”达到120的学号,请你补全代码。
参考程序:
import csv
with open('subways.csv') as f:
rows = list( csv.reader (f))
for row in rows[1:]:
if(int(row[1])>=120):
print(row[0])
模拟考题
考题1 单选题
import csv
headers = ['学号','姓名','分数']
rows = [('202001','张三','98'),
('202002','李四','95'),
('202003','王五','92')]
with open('score.csv','w',encoding='utf8',newline='') as f :
writer = csv.writer(f)
writer.writerow(headers)
writer.writerow(rows)
下列说法不正确的是?( )
A. 在相同路径下生成一个score.csv文件
B. f是一个文件对象
C. headers 是字段名称
D. writer.writerow(rows)将写入多行数据
答案:D
解析:writer.writerows(rows)将写入多行数据
考题2 单选题
with open('mistakes.txt', 'w') as f:
words =['believe','memorize']
f.write('\n'.join(words))
执行该代码后,文件mistakes.txt中的内容是?( )
A. 一行内容为“believe memorize”
B. 一行内容为“believe\n memorize”
C. 第一行内容为“believe”,第二行内容为“memorize”
D. 第一行内容为“believe memorize”,第二行内容为“believe memorize”
答案:C
解析:f.write()是将字符串写入文本文档,遇到'\n'需要换行
考题3 单选题
小红收集了《小王子》中一段文字,存储在“LittlePrince.txt”中,现要读取整段文字内容,返回字符串。
程序代码如下:
f = open("LittlePrince.txt", "r")
articles = _________
f.close()
画线处应填写的语句是?( )
A. f.read()
B. f.readline()
C. f.readlines()
D. f.write()
答案:A
解析:f.read()返回字符串,f.readline()返回一行字符串,f.readlines()返回列表。答案选A。
考题4 单选题
下列关于csv 库中有4个常用的对象的说法,正确的是?( )
A. csv.reader表示以字典的形式写入数据
B. csv.writer表示以列表的形式返回读取的数据
C. csv.DictReader表示以列表的形式返回读取的数据
D. csv.DictWriter表示以字典的形式写入数据
答案:D
解析:csv.reader以列表的形式返回读取的数据,csv.writer以列表的形式写入数据,csv.DictReader以字典的形式返回读取的数据,csv.DictWriter以字典的形式写入数据
考题5 单选题
明明每天坚持背英语单词,他建立了英语单词错题本文件“mistakes.txt”,将每天记错的单词增加到该文件中,下列打开文件的语句最合适的是?( )
A. f = open("mistakes.txt")
B. f = open("mistakes.txt","r")
C. f = open("mistakes.txt","a")
D. f = open("mistakes.txt","w")
答案:C
解析:open函数的第一个参数是文件名称,包括路径;第二个参数是打开的模式mode 'r': 只读(缺省。如果文件不存在,则抛出错误),'w': 只写(如果文件不存在,则自动创建文件),'a': 附加到文件末尾
考题6 单选题
文件“score.csv”中存放了3位同学的成绩数据,小李编写程序读取数据内容,文件内容和程序成功读取界面如图所示。
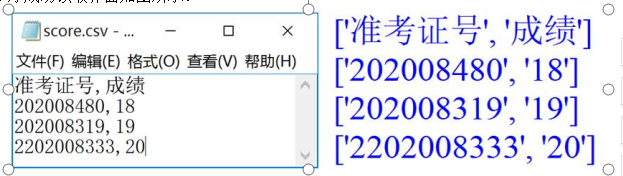
import csv
csv_reader = csv.reader(open(______))
for row in csv_reader:
print(______)
上述程序中划线处应填入?() A. score row
B. score.csv "row"
C. "score" "row"
D. "score.csv" row
答案:D
解析:读取文件时open函数的参数为字符串,应该是完整的文件名加上字符串标识,row代表每一行内容,不应该加字符串标识
考题7 单选题
文件exam.txt与以下代码在同一目录下,其内容是一段文本: bigBen, 下列代码的输出结果是?( )
f = open("exam.txt")
print(f)
f.close()
A. exam.txt
B. exam
C. <_ io.textlowrapper="" ..="">
D. bigBen
答案:C
解析:open()函数打开一个文件, 并返回可以操作这个文件的变量f,并且open()函数有两个参数:文件名和打开模式。本题只是打开了文件,并没有对文件进行操作,因此不会输出文件的内容。print()语句输出的是变量f代表的文件的相关信息: <_ io.TextlOWrapper name='exam.txt' mode='r encoding='cp936'>,若想要输出文件的内容,需要把文件的内容读入,如f1 = f.read()。本题选择C选项。
考题8 判断题
使用内置函数open()的“r”模式打开包含多行内容的文本文件并返回文件对象fp,那么表达式fp.readline()[-1]的值一定为"\n"。( )
答案:正确
解析:使用“r”读取文件返回文件对象后,文件指针指向末位置的后一个位置(即文本内容的下一行),该行为空行。
考题9 判断题
CSV数据存储格式是国际通用的一二维数据存储格式,一般每行一个一维数据,采用逗号分隔。( )
答案:正确
解析:CSV数据存储格式是国际通用的一二维数据存储格式,一般每行一个一维数据,采用逗号分隔
考题10 判断题
二进制文件也可以使用记事本或其他文本编辑器打开,一般来说无法正常查看其中的内容。()
答案:正确
解析:二进制文件也可以使用记事本或其他文本编辑器打开,一般来说无法正常查看其中的内容。